How to Build Redundant Network Architectures on AWS
Learn how to build redundant network architectures on AWS to ensure high availability and avoid costly downtime.
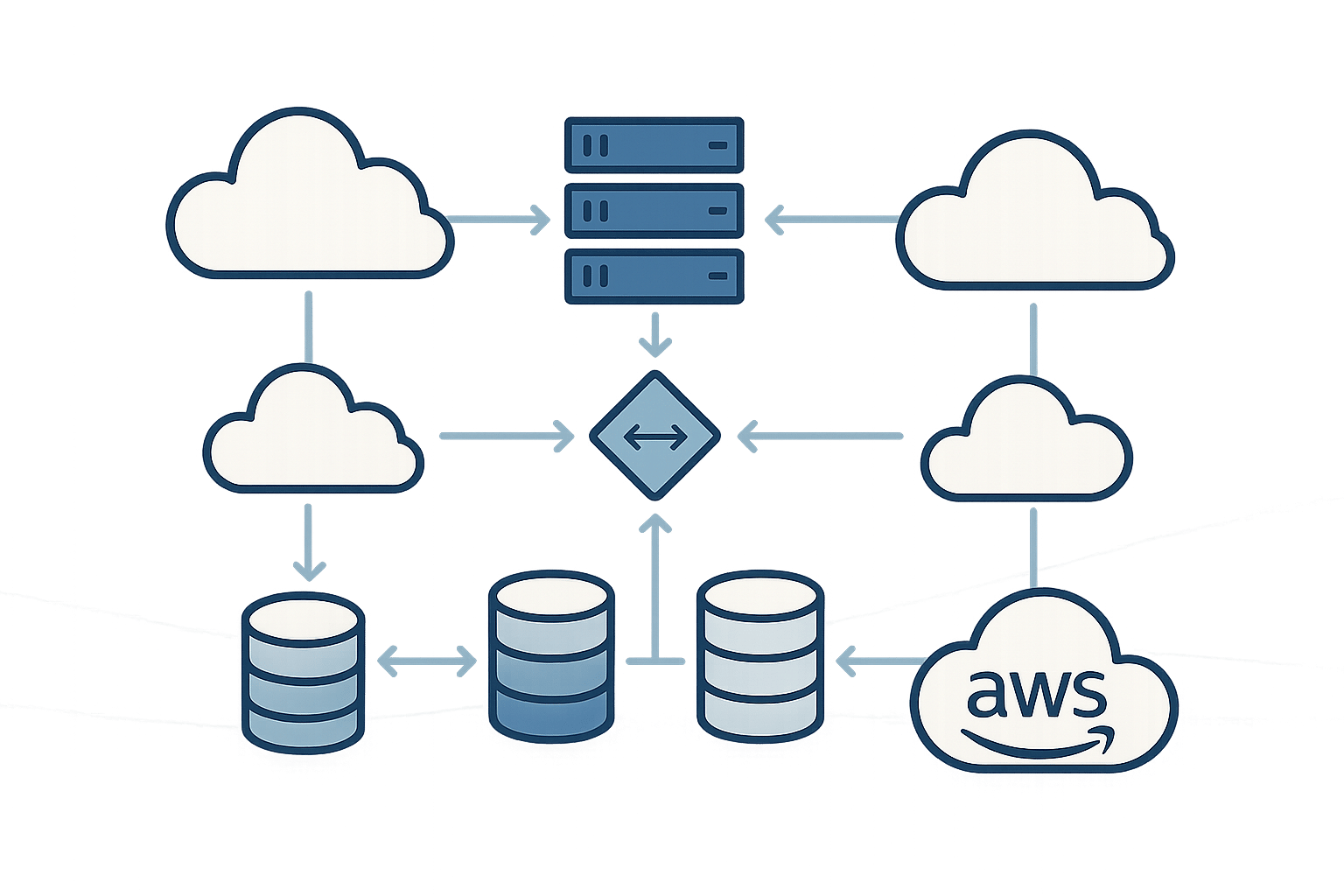
Network downtime can cost businesses money and trust. Building a redundant network on AWS ensures continuous service, avoiding single points of failure. Here's how you can do it:
- Use multiple Availability Zones (AZs): Spread your resources across at least two AZs for resilience.
- Combine Direct Connect and VPN: Use Direct Connect for primary connectivity and VPN as a backup.
- Deploy load balancers and NAT Gateways: Distribute traffic and ensure redundancy for outbound connections.
- Set up DNS failover with Route 53: Automate failover with health checks and routing policies.
- Test regularly: Simulate failures and monitor with CloudWatch to validate redundancy.
Quick Tip: Balance costs by sharing resources within AZs, using VPC endpoints, and leveraging AWS cost management tools like Budgets and Cost Explorer.
This guide walks you through designing reliable, cost-effective AWS networks with redundancy across components, zones, and regions.
AWS Network Redundancy Components
Direct Connect and VPN Setup
Using AWS Direct Connect alongside VPN ensures reliable and redundant network connectivity. Here’s how to set it up effectively:
-
Primary Direct Connect Circuit
Deploy a dedicated 1 Gbps or 10 Gbps Direct Connect circuit at an AWS Direct Connect location. To enhance redundancy, implement additional Direct Connect circuits from separate locations, using BGP routing to enable automatic failover. -
VPN Backup Configuration
Establish multiple VPN tunnels to serve as backup connections. Ensure these tunnels are configured with BGP to handle failover seamlessly.
For managing traffic and securing outbound connectivity, implement load balancers and NAT gateways.
Load Balancers and NAT Gateway Configuration
To achieve high availability, distribute traffic across multiple Availability Zones (AZs). Application Load Balancers (ALBs) or Network Load Balancers (NLBs) are ideal for managing incoming traffic, while NAT Gateways in separate AZs ensure redundancy for outbound internet connectivity. Key steps include:
- Configuring health checks with appropriate thresholds for failover
- Deploying NAT Gateways in at least two AZs
- Setting up routing to handle automatic failover
Once this is in place, focus on improving DNS resilience with Route 53.
DNS Failover with Route 53
Amazon Route 53 offers robust DNS failover capabilities, supported by health checks and flexible routing policies. To strengthen DNS reliability:
- Configure health checks for each endpoint
- Set up failover routing policies, choosing between active-active or active-passive configurations based on your requirements
- Use latency-based routing to improve performance in multi-region setups
- Enable DNS query logging for better visibility and monitoring
For critical workloads, consider these additional options:
- Active-active configurations with weighted routing
- Multi-region DNS failover setups
- Custom health check parameters tailored to your needs
- Automating DNS updates using the AWS SDK
Route 53’s health checks can monitor both endpoint availability and application performance. You can integrate these checks with Amazon CloudWatch for alerts and detailed monitoring.
Building Network Redundancy
Multi-Zone and Region Distribution
To ensure your network is resilient, deploy components across at least two Availability Zones (AZs). This setup should include:
- Public and private VPC subnets
- Redundant network interfaces
- Multiple internet gateways
For even greater reliability, extend your network to multiple Regions. When choosing Regions, consider:
- How close they are to your users
- Regulatory compliance requirements
- Associated costs
- Availability of required AWS services
Once your network spans multiple zones and Regions, set up failover routing to maintain continuous availability.
Setting Up Failover Routing with AWS Route 53
AWS Route 53 can help manage failover routing effectively. Here's how to configure it:
1. Create Primary and Secondary Records
- Set up a primary DNS record with a failover policy.
- Attach health checks to monitor the primary endpoint.
- Add a secondary DNS record to act as a backup.
2. Define Health Check Parameters
- Configure the intervals for health checks.
- Set thresholds for failure detection.
- Ensure health checks are correctly linked to your DNS records.
3. Monitor and Validate
- Use CloudWatch alarms to track status changes.
- Confirm that traffic is rerouted to secondary endpoints when needed.
Once failover routing is configured, regularly test its performance to ensure reliability.
Testing Network Redundancy
Testing is crucial to confirm your redundancy setup works as intended. Use the following methods:
Automated Health Checks
- Monitor endpoints with Route 53.
- Set up alerts using CloudWatch metrics.
- Run failover testing scripts to validate functionality.
Manual Testing Protocol
- Simulate failures of primary components.
- Check if DNS failover works and assess application performance.
- Record recovery times and other metrics for analysis.
Stick to a consistent testing schedule: run automated checks weekly, simulate failovers monthly, and conduct full disaster recovery tests quarterly. This ensures your network remains prepared for unexpected issues.
AWS re:Invent 2022 - Building resilient networks (NET306)

SMB Network Redundancy Guidelines
AWS provides powerful tools for building redundancy, but small and medium-sized businesses (SMBs) need to balance reliability with cost. These guidelines focus on keeping costs manageable while steering clear of common setup mistakes.
Budget-Friendly Redundancy
You don’t have to overspend to build a reliable network. Here’s how to keep redundancy affordable:
Smart VPC Design
- Use at least two Availability Zones (AZs) to ensure service continuity.
- Share NAT Gateways across subnets within the same AZ to cut costs.
- Use VPC endpoints for AWS services to reduce data transfer fees.
Direct Connect Backup
Instead of paying for a second Direct Connect circuit, use AWS Site-to-Site VPN as a backup solution. It’s a reliable and less expensive alternative.
Regional Pricing Awareness
Costs vary by region. For example, running resources in London can be pricier than in Ireland. Factor this into your planning.
Common Setup Errors
Avoid these frequent mistakes that can disrupt your network or inflate costs:
Configuration Pitfalls
| Error | Impact | Solution |
|---|---|---|
| Single-AZ NAT Gateway | Increases the risk of outages | Deploy NAT Gateways in multiple AZs |
| Misconfigured Health Checks | Can cause unnecessary failovers | Set accurate health check thresholds |
| Incomplete Security Groups | May disrupt services | Replicate rules across components |
| Inadequate Monitoring | Delays in failure detection | Use CloudWatch alarms with precise metrics |
Resource Management Missteps
- Over-provisioning redundant components can lead to unnecessary expenses.
- Insufficient IAM permissions might block automated failovers.
- Forgetting to back up critical network settings can leave you vulnerable during recovery.
AWS Cost Management Tools
Once you’ve sidestepped common errors, take advantage of AWS tools to keep redundancy costs under control.
Key Cost Controls
- Set up AWS Budgets with alerts to warn you as spending nears your limits.
- Use Cost Explorer to track spending patterns and find optimisation opportunities.
- Look into Savings Plans if your workloads have predictable usage.
Track Your Spending
AWS Cost and Usage Reports are invaluable for monitoring redundancy expenses. Focus on:
- Data transfer fees between AZs.
- NAT Gateway usage.
- Operational costs for load balancers.
For more tips on balancing cost and reliability, check out AWS Optimization Tips, Costs & Best Practices for Small and Medium sized businesses. This resource offers practical advice and real-world examples to help you stay on budget.
Automate Savings
Use AWS Systems Manager to schedule the shutdown of redundant resources during off-peak hours. This simple step can significantly lower your costs without sacrificing reliability.
These strategies are designed to integrate seamlessly into your AWS redundancy framework, helping you manage costs while maintaining a dependable network.
Summary
Create reliable AWS networks by incorporating key redundant components:
Key Components for Network Redundancy
- Use multiple Availability Zones (AZs).
- Pair Direct Connect with a Site-to-Site VPN as a backup.
- Utilise Route 53 for DNS failover.
- Deploy load balancers across all active zones.
- Set up redundant NAT Gateways.
These strategies align with previously discussed methods for building resilient systems.
Cost-Conscious Implementation
- Share resources strategically within availability zones.
- Use VPC endpoints to reduce data transfer costs.
- Automate schedules for non-critical resources.
- Regularly review expenses with AWS Cost Explorer.
Striking the right balance between cost and performance ensures a reliable and efficient setup.
Key Success Factors
- Configure precise health checks to avoid unnecessary failovers.
- Establish strong IAM permissions for secure access control.
- Keep security group settings accurate and up to date.
- Set up CloudWatch alarms to quickly identify and address issues.
Regional Deployment Tips
Tailor your setup to specific regions for better performance and cost management. For example, consider deploying primarily in London (eu‑west‑2) and using Ireland (eu‑west‑1) as a secondary region. This approach accounts for both pricing differences and latency considerations.
Building redundancy ensures your system remains operational during failures while maintaining availability. Regular testing and monitoring are essential for keeping everything running smoothly.
For more tips on managing costs and optimising your AWS setup, visit AWS Optimization Tips, Costs & Best Practices for Small and Medium sized businesses.
FAQs
How can I balance cost and redundancy when designing a network on AWS?
Balancing cost and redundancy on AWS involves careful planning to ensure high availability without overspending. Start by leveraging AWS services such as VPC, Direct Connect, and Route 53 to design a fault-tolerant architecture. For example, you can use multiple Availability Zones (AZs) within a Region to distribute workloads, ensuring redundancy while keeping data transfer costs manageable.
To optimise costs, consider right-sizing resources, using Reserved Instances or Savings Plans, and monitoring usage with AWS Cost Explorer. Additionally, automating failover with tools like Route 53 can help maintain availability without incurring unnecessary expenses. Properly configuring these services allows you to achieve a balance between resilience and cost-efficiency, tailored to your business needs.
For small and medium-sized businesses (SMBs), focusing on cost optimisation strategies specific to AWS can be especially beneficial to scale effectively while keeping budgets under control.
What are the best practices for testing and ensuring network redundancy on AWS?
Testing and validating network redundancy on AWS is essential to ensure high availability and minimise downtime. Here are some best practices:
- Simulate Failures: Use tools like AWS Fault Injection Simulator to test how your architecture responds to failures in components like EC2 instances, VPCs, or Direct Connect links.
- Monitor Network Health: Leverage AWS services such as CloudWatch and VPC Flow Logs to continuously monitor traffic patterns and detect potential issues.
- Conduct Regular DR Drills: Perform disaster recovery (DR) exercises to validate failover mechanisms, ensuring seamless routing through services like Route 53.
By proactively testing redundancy, you can identify weaknesses and optimise your setup for reliability. For further insights on cost optimisation and best practices for SMBs, consider exploring expert resources tailored to small and medium-sized businesses.
How can using multiple AWS Regions improve network resilience, and what should I keep in mind when choosing Regions?
Using multiple AWS Regions significantly improves network resilience by reducing the risk of service disruptions caused by localised failures, such as natural disasters or outages in a single Region. By distributing your workloads across Regions, you ensure higher availability and better disaster recovery capabilities.
When selecting Regions, consider factors like proximity to your users to minimise latency, compliance with local regulations (e.g., GDPR for the UK), and service availability, as not all AWS services are offered in every Region. Additionally, evaluate the costs of data transfer between Regions, as these can vary and impact your overall budget.